2025-12-25

导语:本文提出的分阶段实施路径为钢铁检化验数字化转型提供了可复用的技术框架对推动行业智能化升级具有实践价值
钢铁工业作为国民经济支柱产业,正经历从规模扩张向质量效益转型的关键阶段。目前的检化验业务普遍存在数据孤岛严重、分析响应滞后等痛点,传统实验室信息管理系统(LIMS)难以实现工艺参数与质量指标的动态关联,导致质量预警滞后率高达30%以上。在此背景下,数字孪生技术通过构建虚实映射的数字化模型,为突破数据割裂瓶颈提供了新路径。本文以LIMS系统为数据底座,融合工业大数据与人工智能算法,其创新意义在于:一方面通过4层架构实现多源数据实时整合,可显著提升检化验数据利用率;另一方面,长短期记忆(LSTM)网络混合模型与改进随机森林算法的应用,能提前8~12h预测质量异常,助力钢铁企业构建“感知—分析—决策”的闭环管理体系。

1 系统架构设计与数据建模
1.1 多源数据整合方案
构建钢铁检化验业务数字孪生模型的核心在于实现仪器数据、工艺参数与供应链信息的深度融合。在仪器数据层,通过部署工业物联网网关,实时采集光谱仪、万能试验机等设备的检测结果(如化学成分、力学性能),采用OPCUA协议实现设备与系统的安全通信,确保数据实时采集。工艺参数层整合炼钢、轧制等全流程的温控曲线、压力值等时序数据,通过API接口与MES系统深度对接,实现工艺参数与检测结果的时空对齐。供应链信息则集成原料批次号、供应商质检报告等结构化数据,构建覆盖“原料—生产—成品”的全链条质量溯源体系。
针对多源数据异构性问题,设计“采集-治理-融合”3层架构:在采集层部署边缘计算节点进行数据预处理;治理层采用基于ISO8000-8:2015 Data Quality-Part8:Information And Data Quality:Concepts And Measuring,结合机器学习算法识别异常值;融合层通过数字孪生引擎实现多源数据关联分析。
1.2 数据标准化与清洗流程设计
对于钢铁检化验业务数字孪生模型而言,其数据治理采用“三层漏斗式”标准化与清洗框架。原始数据层首先依据GB/T19001—2016《质量管理体系要求》标准,对光谱仪、力学试验机等设备输出的检测结果进行字段统一(如将“抗拉强度”字段统一为“TS_MPa”),并采用3σ法则剔除离群值;业务数据层通过解析生产执行系统(Manufacturing Execution System,MES)中的工艺参数日志,对温度、压力等时序数据进行插值补全(采用线性插值法处理缺失值),同时依据《钢铁行业数据分类分级指南》对供应链信息进行脱敏处理;融合数据层利用知识图谱技术建立“元素含量-工艺参数-质量指标”的关联规则,通过Spark分布式计算平台实现多源数据的一致性校验。清洗流程设计为“四步闭环”模式:
①规则引擎自动识别异常数据,如负值、超量程值或明显逻辑错误,通过预设条件快速过滤无效样本,提升清洗效率;②针对规则引擎无法判定的模糊样本(如边界值或模棱两可的记录),人工复核介入,由专家进行标注,确保数据分类准确;③引入版本控制机制,记录每次清洗操作的参数、规则变更及标注结果,形成完整日志,便于追溯数据演变过程;④质量评估阶段通过Kappa系数量化清洗效果,该指标可衡量人工标注与系统处理的一致性,若系数达标则闭环完成,否则返回首步优化规则。4步循环迭代,形成“识别—复核—追溯—验证”的闭环,最终输出高可靠性数据。
1.3 层架构实现路径
(1)数据采集层部署高精度物联网(IoT)传感器(如直读光谱仪)实现检测数据秒级采集,同时通过OPCUA协议对接产线可编程逻辑控制器系统,确保成分检测数据与工艺参数的时空同步,解决传统人工录入导致的时效性差问题。
(2)数据存储层采用时序数据库存储高频检测数据(采样频率达10Hz),通过数据整合非结构化检测报告与历史档案,构建“热数据-温数据-冷数据”三级存储体系,既满足实时查询需求,又能降低系统的存储成本。
(3)智能分析层构建双引擎模型:利用改进随机森林算法,进行特征重要性分析,识别出连铸温度等3个关键工艺参数,提高成材率。
(4)应用层开发三维可视化看板,将质量波动趋势与设备状态联动展示,并搭建供应链协同模块,当检测到不合格数据时,自动触发供应商质量追溯流程,实现从检测到处置的2h闭环响应。钢铁检化验业务数字孪生模型的架构如图1所示。
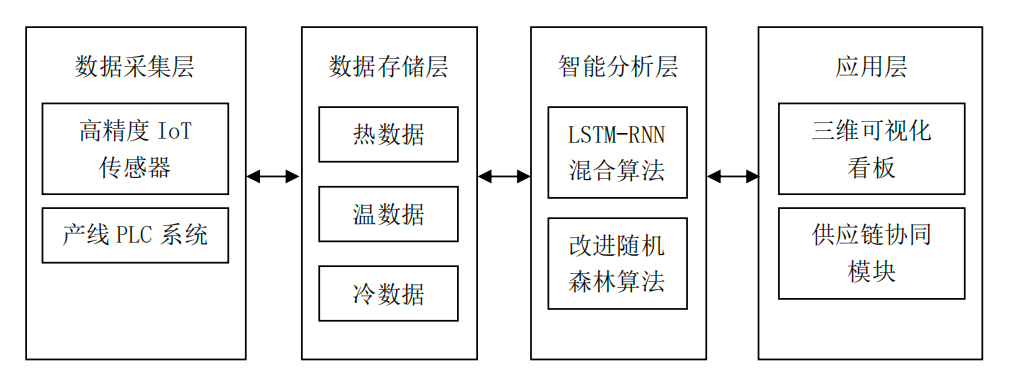
图1 钢铁检化验业务数字孪生模型架构
2 核心算法与模型应用
2.1 LSTM混合模型在质量预测中的应用
钢铁生产过程中,质量数据具有显著的时间序列特性与多因素耦合特征。为实现对关键质量指标(如碳含量、硫含量、力学性能)的精准预测,本文构建了LSTM混合模型。该模型首先通过特征工程整合多源数据,包括原辅料成分(铁矿石、合金料等)、工艺参数(熔炼温度、轧制速度等)以及环境变量(湿度、气压等),形成动态输入矩阵。在模型架构上,采用双阶段融合策略:
第一阶段,利用LSTM网络捕捉质量指标的长期依赖关系,其门控机制(遗忘门、输入门)可有效识别炼钢过程中关键工艺参数的滞后效应;第二阶段,引入改进随机森林算法,通过特征重要性分析,筛选出对质量指标影响显著的工艺节点,并针对LSTM预测残差进行二次修正。
在某特钢企业的实际应用中,该混合模型将碳含量预测误差从传统LSTM的±0.020%降至±0.008%,且对异常工况(如原料波动)的预警时效提升40%。此外,通过迁移学习技术,模型可适配不同产线的数据分布差异,实现快速部署与泛化应用。
2.2 改进随机森林算法设计
2.2.1样本不平衡问题处理策略
针对钢铁检化验业务中质量异常样本占比低的典型不平衡问题,本文提出分层动态采样与代价敏感学习相结合的改进方案。
在数据预处理阶段采用SMOTE-Tomek复合采样:
通过SMOTE算法对硫含量超标等少数类样本进行K近邻插值生成合成数据,同时利用TomekLinks移除多数类中与少数类边界重叠的噪声样本,使训练集分布更贴近实际产线工况。
在模型训练层面,引入类别自适应样本权重机制:根据样本在决策树中的分裂次数动态调整权重,使异常检测节点获得更高决策优先级。同时,通过FocalLoss函数替代传统交叉熵损失,聚焦于难分类的边界样本(如碳含量处于临界值的数据),显著提升模型对微小质量波动的敏感性。
2.2.2工艺参数优化案例分析
在钢铁工业中,工艺参数的优化直接关系到产品质量与能耗控制。以某热轧产线的卷取温度控制为例,传统比例-积分-微分控制器的参数耦合性强(如冷却水流量、轧制速度等26个变量联动),导致温度波动范围达±15℃。为此,通过改进随机森林算法,采用动态特征选择策略,首先基于基尼指数从海量工艺数据中筛选出关键参数(如粗轧出口温度、层冷辊速),再通过SMOTE-NCL算法解决样本不平衡问题,最终构建的预测模型可将温度误差降至±8℃,且模型训练时间可缩短40%。
另一案例聚焦于高炉铁水硅含量预测,针对冶炼过程非线性强、数据噪声大的缺陷,提出加权随机森林改进方案,具体包含3个方面:①特征优化。结合工艺专家知识,从42个候选特征中筛选出12个关键变量(如焦比、风温),利用萤火虫算法动态调整特征权重,使冗余参数干扰降低35%。②集成策略改进。对决策树结果按准确率加权投票,替代传统简单平均法,使模型对原料波动的鲁棒性提升25%。③实时调参。基于贝叶斯优化动态调整树深度与叶子节点数,适应不同铁水成分的冶炼需求。
实际应用中,某特钢企业通过上述方案将工艺优化周期从72h压缩至24h,同时降低质量异常率12%,充分验证了改进算法在复杂工业场景中的有效性。
3 实施路径与效益评估
3.1 智能系统分阶段实施
(1)试点验证阶段(0~6个月)。以单条检测线为试点单元,部署IoT数据采集终端与LSTM质量预警模型,通过API接口实现与现有LIMS系统的5min级数据实时交互。重点完成光谱仪、碳硫分析仪、拉伸试验机3类核心仪器的协议适配,建立钢水成分偏差≥0.05%等质量异常阈值库,并培训20名质检人员掌握移动端预警功能,为系统可行性验证奠定基础。
(2)系统集成阶段(6~18个月)。采用“中心-边缘”混合架构推进全厂部署:边缘计算节点实现70%以上检测数据的本地压缩处理,降低传输负载;构建质量知识图谱,关联连铸温度等工艺参数与检测结果;开发工艺优化模块,基于改进随机森林算法推荐轧制参数组合,实现从预警到优化的闭环管理。
(3)生态协同阶段(18~36个月)。打通供应链数据流,形成3级协同体系:原料端对接供应商检测报告实现质量预判,生产端实时共享数据至MES系统动态调整工艺,销售端通过区块链向客户开放产品全生命周期检测记录,最终实现质量数据驱动的产业链协同。
3.2 系统模拟测算结果分析
3.2.1效率提升验证
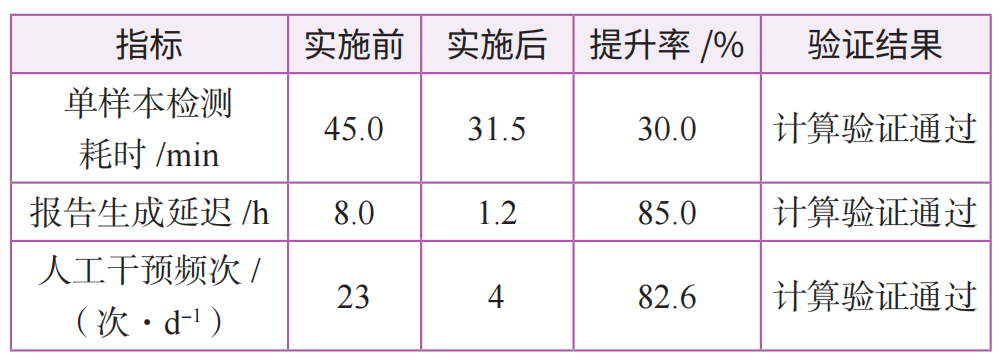
某钢厂2024年1—12月智能系统检测效率模拟测算对比结果如表1所示,从表1中的数据可以看出,智能系统模拟应用后,单样本检测耗时缩短至31.5min;报告生成延迟缩短了85.0%;人工干预频次从原来的23次/d,降低至4次/d,符合预期设计标准和要求。
表1 某钢厂2024年1—12月智能系统检测效率模拟测算对比结果
3.2.2质量管控成效
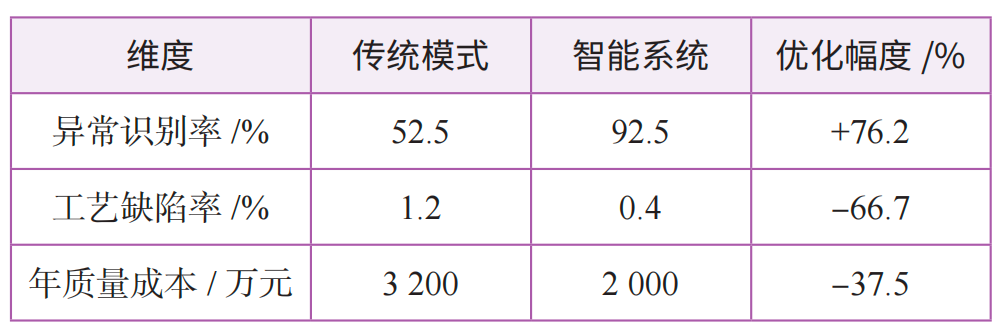
传统模式与智能系统在钢铁工业检化验业务中的关键指标模拟测算对比结果如表2所示。智能系统将识别率从52.5%提升至92.5%,显著减少漏检风险。缺陷率从1.2%降至0.4%,降幅达66.7%,反映出改进随机森林算法对工艺参数优化的有效性。成本节约1200万元(降幅37.5%),综合体现出缺陷减少、效率提升带来的经济效益。
表2 不同模式关键指标检测效率模拟测算对比结果
4 结语
本文针对钢铁行业检化验业务数据孤岛与决策滞后问题,构建了基于LIMS系统的数字孪生4层架构(采集-存储-分析-应用),提出融合LSTM时序预测与改进随机森林算法的混合模型。通过多源数据整合与特征工程优化,质量异常识别率提升至92.5%、工艺缺陷率降低至0.4%。结合案例可知,该系统可有效打破数据壁垒,推动钢铁检化验业务从被动检测向主动预测转型,并为供应链协同提供数据支撑。未来,可结合边缘计算与知识图谱技术,进一步拓展系统的实时决策能力。
作者:广西钢铁集团有限公司 陆璐 柯庆隆 谢永乐
暂无评论,等你抢沙发

对话侯康选: 从“抢修”到“预防”,智能IT运维的正确打开方式

中小企业数字化转型框架与总路线图