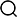2026-06-22

еҜјиҜӯпјҡжң¬з ”究йқўеҗ‘зғ§з»“е·ҘиүәжҷәиғҪеҢ–иҪ¬еһӢж—ЁеңЁжһ„е»әдёҖдёӘиғҪеӨҹж·ұеәҰиһҚеҗҲйўҶеҹҹзҹҘиҜҶдёҺж•°жҚ®жЁЎеһӢзҡ„жҷәиғҪй—®зӯ”зі»з»ҹд»Ҙе®һзҺ°еҜ№дё“дёҡй—®йўҳзҡ„еҮҶзеҸҜйқ дёҺеҸҜи§ЈйҮҠзҡ„иҮӘеҠЁи§Јзӯ”дёәе·ҘиүәдјҳеҢ–дёҺдәәе‘ҳеҹ№и®ӯжҸҗдҫӣж”ҜжҢҒ
зғ§з»“е·ҘиүәжҳҜйҖҡиҝҮй«ҳжё©зғӯеҢ–еӯҰеҸҚеә”е°Ҷй“ҒзҹҝзІүпҪӨзҶ”еүӮпҪӨзҮғж–ҷзӯүж··еҗҲеҺҹж–ҷеӣәз»“жҲҗе…·жңүзү№е®ҡеҶ¶йҮ‘жҖ§иғҪзҡ„еӨҡеӯ”еқ—зҠ¶зғ§з»“зҹҝзҡ„зү©зҗҶеҢ–еӯҰиҝҮзЁӢпҪЎиҜҘиҝҮзЁӢж¶үеҸҠзҮғзғ§пҪӨдј зғӯдј иҙЁпҪӨж¶ІзӣёеҪўжҲҗзӯүеӨҡйҮҚеӨҚжқӮжңәеҲ¶пјҢе‘ҲзҺ°еҮәејәйқһзәҝжҖ§пҪӨеӨ§ж»һеҗҺеҸҠеҠЁжҖҒж—¶еҸҳзӯүзү№еҫҒпјҢе…¶дјҳеҢ–дёҺжҺ§еҲ¶й•ҝжңҹйқўдёҙдёҘеі»жҢ‘жҲҳпҪЎиҝҷдәӣжҢ‘жҲҳзҡ„жң¬иҙЁпјҢеҸҜеҪ’з»“дёәе·Ҙиүә вҖңзҹҘиҜҶвҖқ зҡ„жһҒз«ҜеӨҚжқӮжҖ§дёҺдј з»ҹжҷәиғҪеҢ–ж–№жі• вҖңзҹҘиҜҶвҖқ еӨ„зҗҶиғҪеҠӣд№Ӣй—ҙзҡ„ж №жң¬зҹӣзӣҫпҪЎйҰ–е…ҲпјҢзғ§з»“е·Ҙиүәзҡ„зҹҘиҜҶз»ҙеәҰеӨҡе…ғдё”иҖҰеҗҲзҙ§еҜҶпҪЎе®ғж—ўеҢ…еҗ«й…ҚзўіжҜ”пҪӨзўұеәҰ (R)пҪӨFeO еҗ«йҮҸзӯүеҸӮж•°й—ҙе°ҡдёҚе®Ңе…Ёжё…жҷ°зҡ„жңәзҗҶжҖ§е…іиҒ”пјҢд№ҹи•ҙеҗ«дәҺж“ҚдҪңжүӢеҶҢпҪӨжҠҖжңҜж–ҮзҢ®дёӯзҡ„еӨ§йҮҸж–Үжң¬еҢ–规еҲҷпјҢжӣҙж·ұеәҰ镶еөҢдәҺе·ҘзЁӢеёҲж №жҚ®зҒ«з„°еҪўжҖҒпҪӨж–ӯйқўжғ…еҶөзӯүиҝӣиЎҢеҲӨж–ӯзҡ„йҡҗжҖ§з»ҸйӘҢдёӯпҪЎз„¶иҖҢпјҢеҺҹж–ҷжіўеҠЁеӨ§пҪӨе·ҘеәҸзҺҜиҠӮеӨҡпҪӨеҸҳйҮҸејәиҖҰеҗҲзӯүзү№зӮ№пјҢдҪҝеҫ—иҝҷдәӣеӨҡжәҗејӮжһ„зҹҘиҜҶйҡҫд»Ҙиў«еҪўејҸеҢ–иЎЁеҫҒе’Ңзі»з»ҹеҢ–йӣҶжҲҗпјҢеҜјиҮҙеҪ“еүҚж•°жҚ®й©ұеҠЁжЁЎеһӢжіӣеҢ–иғҪеҠӣдёҚи¶іпјҢиҖҢеҹәдәҺзІҫзЎ®зү©зҗҶж•°еӯҰжЁЎеһӢзҡ„жһ„е»әд№ҹејӮеёёеӣ°йҡҫпҪЎиҝ‘е№ҙжқҘпјҢжҷәиғҪй…Қж–ҷпҪӨзғ§з»“з»ҲзӮ№йў„жөӢзӯүеҹәдәҺдј з»ҹжңәеҷЁеӯҰд№ зҡ„ж–№жі•иҷҪеҸ–еҫ—иҝӣеұ•, дҪҶдё»иҰҒиҒҡз„ҰдәҺж•°жҚ®еұӮйқўзҡ„еұҖйғЁе…іиҒ”жҢ–жҺҳпјҢеңЁиһҚеҗҲж–Үжң¬и§„еҲҷпҪӨ专家з»ҸйӘҢзӯүиҜӯд№үзҹҘиҜҶпјҢд»ҘеҸҠиҝӣиЎҢи·Ёе·ҘеәҸпҪӨеӨҡзӣ®ж Үзҡ„з»јеҗҲжҺЁзҗҶдёҺеҶізӯ–и§ЈйҮҠж–№йқўпјҢд»ҚеӯҳеңЁжҳҫи‘—еұҖйҷҗпҪЎжҚўиЁҖд№ӢпјҢзҺ°жңүж–№жі•йҡҫд»Ҙжһ„е»әдёҖдёӘиғҪеӨҹеғҸйўҶеҹҹ专家дёҖж · вҖңйҳ…иҜ»ж–ҮзҢ®пҪӨзҗҶ解规зЁӢпҪӨеҖҹйүҙжЎҲдҫӢпҪӨжҺЁзҗҶеҶізӯ–вҖқ зҡ„жҷәиғҪдҪ“пҪЎиҝҷе·ІжҲҗдёәеҲ¶зәҰзғ§з»“иҝҮзЁӢе®һзҺ°е…ЁеҹҹжҷәиғҪеҢ–еҚҮзә§зҡ„ж ёеҝғ瓶йўҲпҪЎ
еӨ§иҜӯиЁҖжЁЎеһӢ (Large Language Models,LLMs) зҡ„е…ҙиө·пјҢдёәз ҙи§ЈдёҠиҝ°зҹҘиҜҶ瓶йўҲжҸҗдҫӣдәҶеҸҳйқ©жҖ§жҖқи·ҜпҪЎLLMs еҮӯеҖҹеңЁеҚғдәҝзә§ж–Үжң¬дёҠйў„и®ӯз»ғиҺ·еҫ—зҡ„ејәеӨ§иҜӯд№үзҗҶи§ЈпҪӨзҹҘиҜҶжіӣеҢ–дёҺйҖ»иҫ‘жҺЁзҗҶиғҪеҠӣпјҢжңүжңӣе°ҶеҲҶж•Јзҡ„е·Ҙиүәж–ҮзҢ®пҪӨжЎҲдҫӢжҠҘе‘ҠпҪӨж“ҚдҪң规зЁӢзӯүйқһз»“жһ„еҢ–ж–Үжң¬зҹҘиҜҶиҪ¬еҢ–дёәеҸҜи®Ўз®—пҪӨеҸҜжҹҘиҜўзҡ„ж•°еӯ—еҢ–иө„дә§пҪЎе…¶ж ёеҝғд»·еҖјеңЁдәҺиғҪеӨҹзҗҶи§Је’Ңз”ҹжҲҗиҮӘ然иҜӯиЁҖпјҢд»ҺиҖҢзӣҙжҺҘеӨ„зҗҶзғ§з»“йўҶеҹҹжңҖж ёеҝғзҡ„зҹҘиҜҶиҪҪдҪ“пјҢдёәжһ„е»әе…·еӨҮ вҖңзҹҘиҜҶйҳ…иҜ»вҖқ дёҺ вҖңеҶізӯ–и§ЈйҮҠвҖқ иғҪеҠӣзҡ„жҷәиғҪзі»з»ҹеҘ е®ҡдәҶеҹәзЎҖпҪЎеҪ“еүҚпјҢеӨ§иҜӯиЁҖжЁЎеһӢеңЁй’ўй“ҒеҶ¶йҮ‘йўҶеҹҹзҡ„еҸ‘еұ•жӯЈиҝ…йҖҹд»ҺжҰӮеҝөйӘҢиҜҒиө°еҗ‘规模еҢ–еә”з”ЁпјҢжҲҗдёәиЎҢдёҡж•°еӯ—еҢ–иҪ¬еһӢе’Ңеҹ№иӮІж–°з”ҹдә§еҠӣзҡ„е…ій”®й©ұеҠЁеҠӣпҪЎйҷҶиөҹйҹ¬зӯүжҺўзҙўдәҶ3 з§Қжһ„е»әй’ўй“ҒйўҶеҹҹеӨ§жЁЎеһӢзҡ„дё»жөҒж–№жі•пјҢдёәй’ўй“ҒиЎҢдёҡеҸҠе…¶д»–еһӮзӣҙйўҶеҹҹжһ„е»әдё“з”ЁеӨ§жЁЎеһӢжҸҗдҫӣдәҶе®һи·өжҢҮеҜјдёҺж–№жі•и®әеҸӮиҖғпҪЎ
然иҖҢпјҢзҺ°жңүе·ҘдёҡеӨ§жЁЎеһӢзҡ„еә”з”ЁеӨҡиҒҡз„ҰдәҺз”ҹдә§и°ғеәҰпҪӨи®ҫеӨҮж•…йҡңиҜҠж–ӯзӯүзӣёеҜ№з»“жһ„еҢ–пҪӨ规еҲҷеҢ–зҡ„еңәжҷҜпҪЎй’ҲеҜ№еҰӮзғ§з»“иҝҷиҲ¬еҢ…еҗ«еӨҚжқӮзү©зҗҶеҢ–еӯҰеҸҚеә”пҪӨеӨҡеҸҳйҮҸејәиҖҰеҗҲдё”дёҘйҮҚдҫқиө–йҡҗжҖ§дёҺж–Үжң¬зҹҘиҜҶзҡ„е·ҘиүәиҝҮзЁӢпјҢеҰӮдҪ•жһ„е»әдё“з”ЁеӨ§жЁЎеһӢпјҢд»ҚжҳҜдёҖдёӘдәҹеҫ…ж·ұе…ҘжҺўзҙўзҡ„з ”з©¶з©әзҷҪпҪЎе°Ҷ LLMs еј•е…Ҙзғ§з»“е·ҘиүәжҷәиғҪеҢ–, е…¶ж ёеҝғд»·еҖјеңЁдәҺе…¶ејәеӨ§зҡ„иҜӯд№үзҗҶи§ЈдёҺзҹҘиҜҶиһҚеҗҲиғҪеҠӣпјҢжңүжңӣжү“йҖҡж–Үжң¬и§„еҲҷпҪӨ专家з»ҸйӘҢдёҺиҝҮзЁӢж•°жҚ®д№Ӣй—ҙзҡ„еЈҒеһ’пјҢжһ„е»әдёҖдёӘиғҪеӨҹ вҖңзҗҶи§ЈвҖқ е·ҘиүәпҪӨвҖңеҖҹйүҙвҖқ зҹҘиҜҶ并иҝӣиЎҢ вҖңжҺЁзҗҶвҖқ иҫ…еҠ©еҶізӯ–зҡ„жҷәиғҪзі»з»ҹпҪЎ
еҹәдәҺжӯӨпјҢжң¬з ”究旨еңЁзӣҙйқўзғ§з»“е·Ҙиүәзҡ„ вҖңзҹҘиҜҶ瓶йўҲвҖқ, еӣҙз»• LLMs зҡ„йўҶеҹҹеҢ–еә”з”ЁпјҢжһ„е»әй«ҳиҙЁйҮҸзҡ„зғ§з»“дё“дёҡж•°жҚ®йӣҶпјҢ并йҮҮз”ЁиһҚеҗҲ LoRA еҸӮж•°й«ҳж•Ҳеҫ®и°ғдёҺжЈҖзҙўеўһејәз”ҹжҲҗ (RAG) зҡ„жҠҖжңҜи·ҜзәҝпјҢжһ„е»әдёҖдёӘе…је…·йўҶеҹҹзҹҘиҜҶж·ұеәҰдёҺз”ҹжҲҗеҶ…е®№дәӢе®һжҖ§зҡ„зғ§з»“е·ҘиүәжҷәиғҪй—®зӯ”дёҺиҜҠж–ӯжЁЎеһӢпҪЎжң¬з ”究дёҚд»…иҮҙеҠӣдәҺеЎ«иЎҘиҜҘйўҶеҹҹеә”з”Ёз ”з©¶зҡ„з©әзҷҪпјҢжӣҙжңҹжңӣдёәи§ЈеҶіжөҒзЁӢе·Ҙдёҡдёӯжҷ®йҒҚеӯҳеңЁзҡ„зҹҘиҜҶйӣҶжҲҗдёҺеҲ©з”ЁйҡҫйўҳпјҢжҸҗдҫӣдёҖжқЎеҸҜйӘҢиҜҒпҪӨеҸҜиҗҪең°зҡ„жҠҖжңҜж–°и·Ҝеҫ„пҪЎ
1 жҠҖжңҜжһ¶жһ„
жң¬з ”究旨еңЁжһ„е»әйқўеҗ‘зғ§з»“е·Ҙиүәзҡ„жҷәиғҪй—®зӯ”дёҺиҜҠж–ӯеӨ§иҜӯиЁҖжЁЎеһӢпјҢе…¶жҠҖжңҜж ёеҝғж¶өзӣ–йўҶеҹҹж•°жҚ®жһ„е»әпҪӨжЁЎеһӢй«ҳж•ҲйҖӮй…ҚпҪӨзҹҘиҜҶеўһејәз”ҹжҲҗд»ҘеҸҠзі»з»ҹеҢ–иҜ„дј°дёҺйғЁзҪІпҪЎж•ҙдҪ“жһ¶жһ„йҒөеҫӘ вҖңж•°жҚ® - жЁЎеһӢ - зҹҘиҜҶ - еә”з”ЁвҖқ зҡ„еҚҸеҗҢи®ҫи®ЎжҖқи·ҜпјҢеҰӮеӣҫ1жүҖзӨәпҪЎйҰ–е…ҲпјҢй’ҲеҜ№зғ§з»“йўҶеҹҹй«ҳиҙЁйҮҸж•°жҚ®зЁҖзјәзҡ„зҺ°зҠ¶пјҢзі»з»ҹеҢ–ең°жһ„е»әдәҶдё“дёҡй—®зӯ”ж•°жҚ®йӣҶпјӣеңЁжӯӨеҹәзЎҖдёҠпјҢйҖүеҸ–йҖӮе®ңзҡ„еҹәеә§жЁЎеһӢпјҢ并йҮҮз”ЁеҸӮж•°й«ҳж•Ҳеҫ®и°ғжҠҖжңҜ (LoRA) иҝӣиЎҢйўҶеҹҹзҹҘиҜҶжіЁе…ҘпјӣеҗҢж—¶пјҢеј•е…ҘжЈҖзҙўеўһејәз”ҹжҲҗ (RAG) жңәеҲ¶пјҢеҠЁжҖҒиһҚеҗҲеӨ–йғЁзҹҘиҜҶеә“д»ҘзЎ®дҝқз”ҹжҲҗеҶ…е®№зҡ„еҮҶзЎ®жҖ§дёҺеҗҲ规жҖ§пјӣжңҖеҗҺпјҢжһ„е»әдәҶиҙҙеҗҲзғ§з»“е·Ҙиүәзү№зӮ№зҡ„иҜ„дј°дҪ“系并ејҖеҸ‘дәҶдәӨдә’ејҸеә”з”Ёе№іеҸ°пҪЎиҜҘжһ¶жһ„дёәзғ§з»“е·ҘиүәзҹҘиҜҶзҡ„ж•°еӯ—еҢ–з®ЎзҗҶдёҺжҷәиғҪеҢ–еә”з”ЁжҸҗдҫӣдәҶе®Ңж•ҙзҡ„жҠҖжңҜи§ЈеҶіж–№жЎҲпҪЎ
еӣҫ 1 зғ§з»“жҷәж…§й—®зӯ”жҠҖжңҜжһ¶жһ„
1.1 ж•°жҚ®жҸҗеҸ–дёҺеӨ„зҗҶ
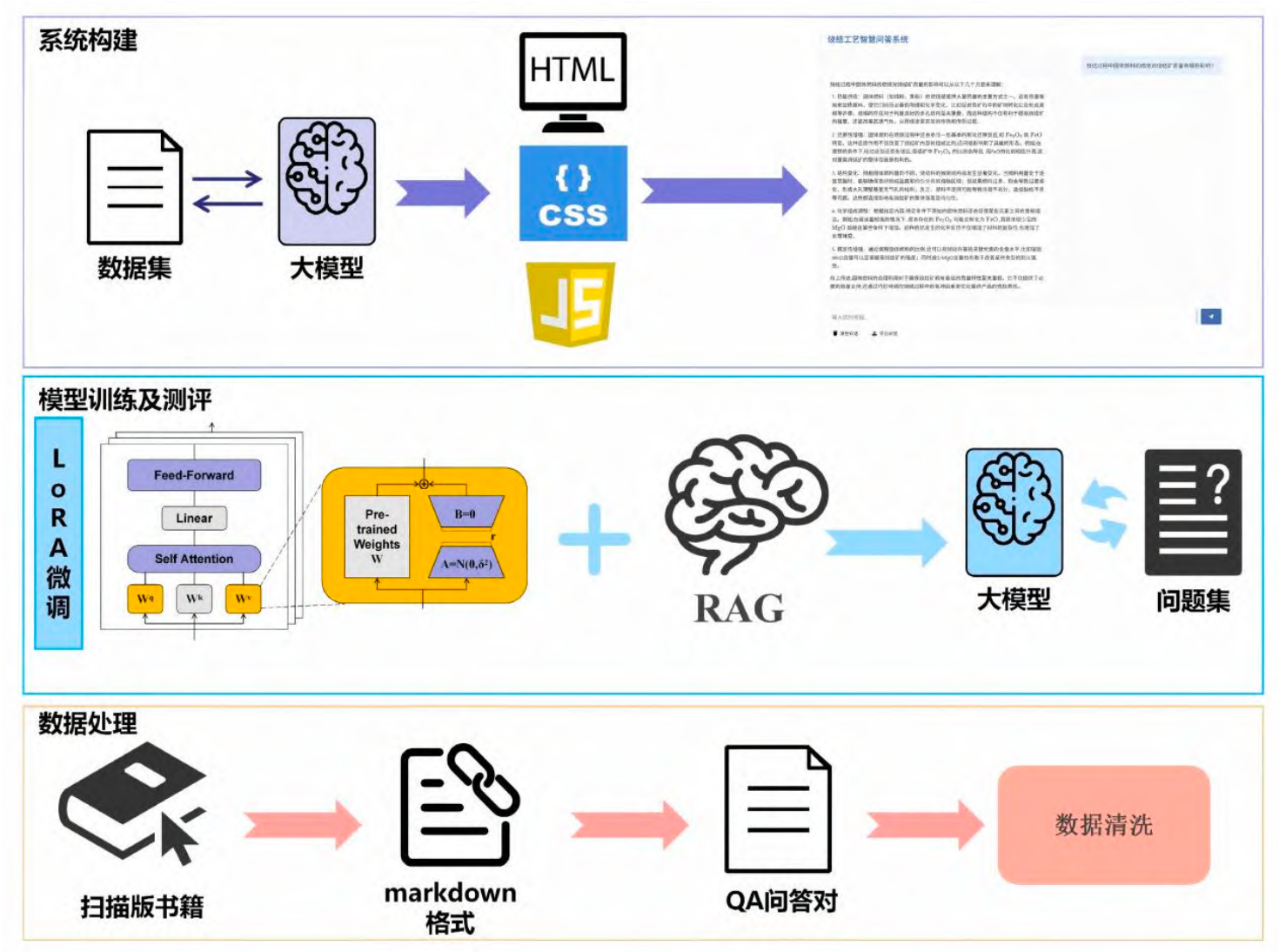
й«ҳиҙЁйҮҸйўҶеҹҹж•°жҚ®йӣҶзҡ„жһ„е»әжҳҜзғ§з»“е·ҘиүәеӨ§жЁЎеһӢз ”з©¶зҡ„еҹәзҹіпҪЎй’ҲеҜ№зғ§з»“йўҶеҹҹе…¬ејҖж•°жҚ®йӣҶзЁҖзјәпҪӨзҹҘиҜҶеӨҡеӯҳеӮЁдәҺйқһз»“жһ„еҢ–ж–Үжң¬дёӯзҡ„зҺ°зҠ¶пјҢжң¬з ”究и®ҫи®ЎдәҶдёҖеҘ—д»ҺеӨҡжәҗеҺҹе§Ӣиө„ж–ҷеҲ°ж ҮеҮҶеҢ–й—®зӯ”еҜ№зҡ„ж•°жҚ®еӨ„зҗҶжөҒзЁӢ (еӣҫ 2)пҪЎж•°жҚ®дё»иҰҒжқҘжәҗдәҺдёӨзұ»пјҡ1) жү«жҸҸзүҲдё“дёҡд№ҰзұҚдёҺжҠҖжңҜжҠҘе‘Ҡпјӣ2) еӯҰжңҜж•°жҚ®еә“ (еҰӮзҹҘзҪ‘пҪӨдёҮж–№) дёӯзҡ„жңҹеҲҠи®әж–ҮпҪӨеӯҰдҪҚи®әж–ҮеҸҠдё“еҲ©гҖӮ
еӣҫ 2 зғ§з»“йўҶеҹҹж•°жҚ®йӣҶжһ„е»әжөҒзЁӢ
еҜ№дәҺжү«жҸҸж–ҮжЎЈпјҢйҰ–е…Ҳз»ҹдёҖиҪ¬жҚўдёә PDF ж јејҸпјҢйҡҸеҗҺйҮҮз”Ё PaddleOCR дёҺ LayoutLMv3 зӯүжЁЎеһӢиҝӣиЎҢзүҲйқўеҲҶжһҗдёҺж–Үжң¬жҸҗеҸ–пјҢе°ҶеҶ…е®№иҝҳеҺҹдёәз»“жһ„еҢ–зҡ„ Markdown ж јејҸпҪЎеҜ№дәҺеӯҰжңҜж–ҮзҢ®пјҢеҲҷйҖҡиҝҮжҺҘеҸЈжү№йҮҸиҺ·еҸ–е…ғж•°жҚ® (ж ҮйўҳпҪӨж‘ҳиҰҒзӯү) еҸҠе…Ёж–ҮдҝЎжҒҜпҪЎе…ій”®жӯҘйӘӨеңЁдәҺеҲ©з”ЁеӨ–йғЁеӨ§иҜӯиЁҖжЁЎеһӢпјҢеҹәдәҺжҸҗеҸ–зҡ„ Markdown ж–Үжң¬жҲ–ж–ҮзҢ®еҶ…е®№пјҢйҖҡиҝҮзІҫеҝғи®ҫи®Ўзҡ„жҸҗзӨәиҜҚе·ҘзЁӢиҮӘеҠЁеҢ–з”ҹжҲҗдёҺзғ§з»“е·Ҙиүәзӣёе…ізҡ„й—®зӯ”еҜ№пҪЎдёәзЎ®дҝқж•°жҚ®иҙЁйҮҸпјҢеҗҺз»ӯејҖеҸ‘дәҶиҫ…еҠ©е·Ҙ具并иҫ…д»Ҙдәәе·Ҙж ЎеҜ№пјҢйҮҚзӮ№дҝ®жӯЈж јејҸй”ҷиҜҜпҪӨе…¬ејҸжёІжҹ“ејӮеёёеҸҠеҶ…е®№дёҚдёҖиҮҙзӯүй—®йўҳпҪЎжңҖз»ҲпјҢжһ„е»әдәҶдёҖдёӘеҢ…еҗ« 35019 жқЎй«ҳиҙЁйҮҸй—®зӯ”еҜ№зҡ„зғ§з»“е·Ҙиүәдё“з”Ёж•°жҚ®йӣҶпјҢдёәеҗҺз»ӯжЁЎеһӢи®ӯз»ғдёҺзҹҘиҜҶжЈҖзҙўжҸҗдҫӣдәҶеҸҜйқ зҡ„зҹҘиҜҶжқҘжәҗпҪЎ
1.2 еҹәеә§жЁЎеһӢйҖүжӢ©
еҹәеә§жЁЎеһӢзҡ„йҖүжӢ©йңҖеңЁжЁЎеһӢиғҪеҠӣпҪӨж•°жҚ®и§„жЁЎдёҺи®Ўз®—иө„жәҗй—ҙеҸ–еҫ—е№іиЎЎпҪЎTransformer жһ¶жһ„еҘ е®ҡдәҶеӨ§иҜӯиЁҖжЁЎеһӢзҡ„еҹәзЎҖпјҢе…¶жј”иҝӣе‘ҲзҺ°еҮәеҗ‘еһӮзӣҙйўҶеҹҹж·ұеҢ–еә”з”Ёзҡ„и¶ӢеҠҝпҪЎеӨ§жЁЎеһӢзҡ„еҸӮж•°йҮҸйҖҡеёёдёҺе…¶иғҪеҠӣиҫ№з•ҢжӯЈзӣёе…іпјҢдҪҶеңЁжңүйҷҗзҡ„йўҶеҹҹж•°жҚ®дёӢпјҢиҝҮеӨ§зҡ„еҸӮ数规模жҳ“еҜјиҮҙиҝҮжӢҹеҗҲпҪЎеҹәдәҺжң¬з ”究жүҖжһ„е»әзҡ„ 35019 жқЎзғ§з»“дё“дёҡж•°жҚ®еҸҠеҸҜ用硬件иө„жәҗ (дёӨеј NVIDIA RTX 4090), жҲ‘们йҖүжӢ©дәҶ DeepSeek-R1-Distill-Qwen-7BдҪңдёәеҹәеә§жЁЎеһӢпҪЎиҜҘжЁЎеһӢдёәз»ҸиҝҮи’ёйҰҸзҡ„ 7B еҸӮж•°жЁЎеһӢпјҢеңЁдҝқжҢҒиҫғејәжҺЁзҗҶиғҪеҠӣзҡ„еҗҢж—¶пјҢеҜ№и®Ўз®—иө„жәҗзҡ„иҰҒжұӮзӣёеҜ№йҖӮдёӯпјҢйқһеёёйҖӮеҗҲеңЁжңүйҷҗ规模дҪҶй«ҳд»·еҖјзҡ„зғ§з»“йўҶеҹҹж•°жҚ®дёҠиҝӣиЎҢй«ҳж•Ҳзҡ„еҫ®и°ғдёҺйҖӮй…ҚпјҢдёәеҗҺз»ӯиһҚеҗҲйўҶеҹҹзҹҘиҜҶеҘ е®ҡдәҶиүҜеҘҪеҹәзЎҖпҪЎ
1.3 LoRA еҫ®и°ғ
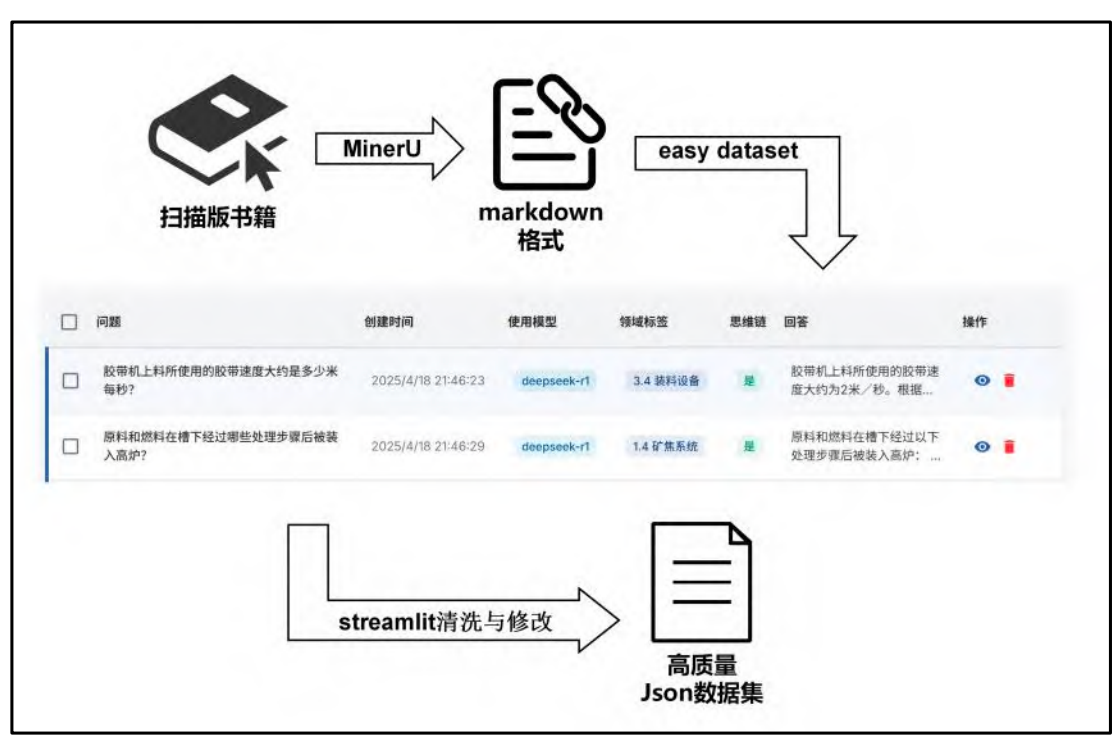
дёәдҪҝйҖҡз”ЁеӨ§жЁЎеһӢзІҫеҮҶжҺҢжҸЎзғ§з»“е·Ҙиүәзҡ„дё“дёҡжңҜиҜӯпҪӨеҸӮж•°й—ҙеӨҚжқӮе…іиҒ”еҸҠйўҶеҹҹзү№жңүиЎЁиҫҫпјҢеҜ№е…¶иҝӣиЎҢеҫ®и°ғиҮіе…ійҮҚиҰҒпҪЎиҖғиҷ‘еҲ°йўҶеҹҹж•°жҚ®и§„жЁЎжңүйҷҗеҸҠи®Ўз®—ж•ҲзҺҮпјҢжң¬з ”究йҮҮз”ЁдҪҺ秩иҮӘйҖӮеә” (LoRA) иҝҷдёҖеҸӮж•°й«ҳж•Ҳеҫ®и°ғж–№жі•пҪЎеҰӮеӣҫ 3 жүҖзӨәпјҢLoRA зҡ„ж ёеҝғжҖқжғіжҳҜдёҚеҜ№йў„и®ӯз»ғжЁЎеһӢзҡ„е…ЁйҮҸеҸӮж•° W иҝӣиЎҢжӣҙж–°пјҢиҖҢжҳҜйҖҡиҝҮеј•е…ҘдёӨдёӘдҪҺ秩зҹ©йҳө A е’Ң B зҡ„д№ҳз§Ҝ (BA) жқҘй—ҙжҺҘеӯҰд№ еҸӮж•°еўһйҮҸО”WвүҲBA, еҫ®и°ғд№ӢеҗҺзҡ„жқғйҮҚзҹ©йҳөжӣҙж–°дёәWвҖҷ=W+О”W=W+BAпҪЎиҝҷз§Қж–№ејҸд»…йңҖи®ӯз»ғжһҒе°‘йҮҸзҡ„еҸӮж•°пјҢеҚҙиғҪжңүж•Ҳе°Ҷзғ§з»“е·ҘиүәзҹҘиҜҶжіЁе…ҘжЁЎеһӢпјҢеңЁжҳҫи‘—йҷҚдҪҺи®Ўз®—ејҖй”Җе’ҢеӯҳеӮЁйңҖжұӮзҡ„еҗҢж—¶пјҢиҫғеҘҪең°жҺ§еҲ¶дәҶеңЁжңүйҷҗж•°жҚ®дёҠеҸҜиғҪеҮәзҺ°зҡ„иҝҮжӢҹеҗҲйЈҺйҷ©пјҢдҪҝжЁЎеһӢеңЁдҝқз•ҷйҖҡз”ЁиҜӯиЁҖзҗҶи§ЈиғҪеҠӣзҡ„еҹәзЎҖдёҠпјҢж·ұеәҰиһҚеҗҲзғ§з»“е·Ҙиүәзҡ„дё“дёҡзү№жҖ§пҪЎ
еӣҫ 3 LoRA еҺҹзҗҶеӣҫ
1.4 жЈҖзҙўеўһејәз”ҹжҲҗ (RAG)
дёәйҒҸеҲ¶еӨ§жЁЎеһӢеңЁдё“дёҡеңәжҷҜдёӢзҡ„ вҖңе№»и§үвҖқ й—®йўҳпјҢ并确дҝқз”ҹжҲҗзҡ„е»әи®®з¬ҰеҗҲзғ§з»“е·Ҙиүә规зЁӢдёҺзү©зҗҶзәҰжқҹпјҢжң¬з ”究йӣҶжҲҗдәҶжЈҖзҙўеўһејәз”ҹжҲҗ (RAG) жңәеҲ¶пҪЎRAG зҡ„е®һж–ҪеҲҶдёәзҰ»зәҝзҹҘиҜҶеә“жһ„е»әдёҺеңЁзәҝжЈҖзҙўз”ҹжҲҗдёӨйҳ¶ж®өпҪЎ
зҰ»зәҝйҳ¶ж®өпјҢе°Ҷ 2.1 иҠӮжһ„е»әзҡ„зғ§з»“йўҶеҹҹж•°жҚ®йӣҶдҪңдёәзҹҘиҜҶжәҗпјҢеҜ№е…¶иҝӣиЎҢж–Үжң¬еҲҶеқ—пҪӨеҗ‘йҮҸеҢ–еөҢе…Ҙ (йҮҮз”ЁеҰӮ BGEпҪӨ M3E зӯүеөҢе…ҘжЁЎеһӢ) 并еӯҳе…Ҙеҗ‘йҮҸж•°жҚ®еә“ (еҰӮ FAISS)пҪЎ
еңЁзәҝйҳ¶ж®өпјҢеҪ“з”ЁжҲ·жҸҗй—®ж—¶пјҢзі»з»ҹйҰ–е…Ҳд»Һеҗ‘йҮҸж•°жҚ®еә“дёӯжЈҖзҙўеҮәдёҺй—®йўҳиҜӯд№үжңҖзӣёе…ізҡ„иӢҘе№ІзҹҘиҜҶзүҮж®өпҪЎйҡҸеҗҺпјҢе°ҶиҝҷдәӣзүҮж®өдҪңдёәдёҠдёӢж–ҮдҝЎжҒҜдёҺз”ЁжҲ·й—®йўҳдёҖеҗҢжһ„йҖ жҲҗеўһејәжҸҗзӨә (Prompt), иҫ“е…ҘиҮіе·Іеҫ®и°ғзҡ„еӨ§жЁЎеһӢдёӯз”ҹжҲҗжңҖз»Ҳзӯ”жЎҲпҪЎжӯӨжңәеҲ¶зЎ®дҝқдәҶжЁЎеһӢзҡ„еӣһзӯ”е§Ӣз»Ҳй”ҡе®ҡеңЁжқғеЁҒзҡ„йўҶеҹҹзҹҘиҜҶеә“еҶ…пјҢжһҒеӨ§жҸҗеҚҮдәҶиҫ“еҮәеҶ…е®№зҡ„еҮҶзЎ®жҖ§дёҺеҸҜйқ жҖ§пҪЎ
1.5 иҜ„дј°ж–№ејҸжһ„е»ә
дёә科еӯҰиҜ„дј°жүҖжһ„е»әжЁЎеһӢзҡ„жҖ§иғҪпјҢжң¬з ”究и®ҫи®ЎдәҶдёҖеҘ—й’ҲеҜ№зғ§з»“е·Ҙиүәзү№зӮ№зҡ„иҮӘеҠЁеҢ–иҜ„дј°ж–№жЎҲпҪЎжҲ‘们жһ„е»әдәҶдёҖдёӘеҢ…еҗ« 2000 йҒ“иҜ•йўҳзҡ„иҜ„жөӢйӣҶпјҢйўҳеһӢж¶өзӣ–йҖүжӢ©йўҳпҪӨеҲӨж–ӯйўҳдёҺй—®зӯ”йўҳпјҢеҶ…е®№е…Ёйқўж¶үеҸҠзғ§з»“еҺҹзҗҶпҪӨе·ҘиүәеҸӮж•°пҪӨиҙЁйҮҸжҺ§еҲ¶зӯүж ёеҝғзҹҘиҜҶпјҢиҜ•йўҳж ·дҫӢи§ҒиЎЁ 1пҪЎиҜ„дј°ж—¶пјҢе°ҶжЁЎеһӢеҜ№иҜ•йўҳзҡ„з”ҹжҲҗзӯ”жЎҲдёҺж ҮеҮҶзӯ”жЎҲдёҖеҗҢжҸҗдәӨз»ҷдёҖдёӘй«ҳжҖ§иғҪиҜ„е®ЎеӨ§жЁЎеһӢ (еҰӮ DeepSeek-R1), дҫқжҚ®иЎЁ 2 жүҖе®ҡд№үзҡ„иҜ„еҲҶ规еҲҷиҝӣиЎҢжү“еҲҶпҪЎиҜҘ规еҲҷд»Һ вҖңйҖ»иҫ‘жҖ§пҪӨеҸҜиҜ»жҖ§пҪӨиҝһиҙҜжҖ§вҖқ(0~3 еҲҶ) е’Ң вҖңеҶ…е®№жӯЈзЎ®жҖ§еҸҠе…¶дёҺж ҮеҮҶзӯ”жЎҲзҡ„иҝ‘дјјзЁӢеәҰвҖқ(0~7 еҲҶ) дёӨдёӘз»ҙеәҰиҝӣиЎҢз»јеҗҲиҜ„д»·пјҢжҖ»еҲҶ10 еҲҶпҪЎжӯӨж–№жі•иғҪй«ҳж•ҲпҪӨзӣёеҜ№е®ўи§Ӯең°иЎЎйҮҸжЁЎеһӢеңЁдё“дёҡй—®зӯ”дёҠзҡ„йҖ»иҫ‘жөҒз•…еәҰдёҺдәӢе®һеҮҶзЎ®жҖ§пҪЎ
иЎЁ 1 жөӢиҜ„иҜ•йўҳж ·дҫӢ

иЎЁ 2 жөӢиҜ„иҜ„еҲҶ规еҲҷ

2 иҜ•йӘҢз»“жһң
2.1 иҜ•йӘҢеҸӮж•°и®ҫзҪ®
дёәзЎ®е®ҡеңЁзү№е®ҡ硬件 (2 еј NVIDIA RTX 4090) дёҺж•°жҚ®и§„жЁЎ (35019 жқЎй—®зӯ”еҜ№) дёӢзҡ„жңҖдјҳеҫ®и°ғзӯ–з•ҘпјҢжң¬з ”究и®ҫи®ЎдәҶдёӨз»„еҜ№з…§иҜ•йӘҢпјҢж—ЁеңЁзі»з»ҹжҖ§ең°жҺўз©¶жЁЎеһӢеҸӮж•°йҮҸдёҺе…ій”®и®ӯз»ғеҸӮж•°еҜ№жҖ§иғҪзҡ„еҪұе“ҚпҪЎз¬¬ 1 з»„иҜ•йӘҢиҒҡз„ҰдәҺеҹәеә§жЁЎеһӢеҸӮ数规模зҡ„йҖүжӢ©пҪЎзғ§з»“йўҶеҹҹж•°жҚ®и§„жЁЎжңүйҷҗзҡ„еүҚжҸҗдёӢпјҢжЁЎеһӢе®№йҮҸдёҺиҝҮжӢҹеҗҲйЈҺйҷ©йңҖи°Ёж…ҺжқғиЎЎпҪЎиҜ•йӘҢйҖүз”ЁеҗҢдёҖзі»еҲ— (еҹәдәҺ DeepSeek и’ёйҰҸзҡ„ Qwen) дҪҶеҸӮж•°йҮҸеҲҶеҲ«дёә 1.5B е’Ң 7B зҡ„жЁЎеһӢпјҢеңЁдҝқжҢҒе…¶д»–и¶…еҸӮж•°дёҖиҮҙзҡ„жқЎд»¶дёӢиҝӣиЎҢ LoRA еҫ®и°ғпҪЎ7B жЁЎеһӢеңЁйҖ»иҫ‘жҖ§ (2.6 vs. 2.2) дёҺжӯЈзЎ®жҖ§ (4.9 vs. 3.8) дёҠеқҮжҳҫи‘—дјҳдәҺ 1.5B жЁЎеһӢ (иЎЁ 3)пҪЎиҝҷиЎЁжҳҺпјҢеҜ№дәҺжң¬з ”究жүҖжһ„е»әзҡ„дёҮжқЎзә§й«ҳиҙЁйҮҸзғ§з»“ж•°жҚ®йӣҶпјҢ7B еҸӮж•°жЁЎеһӢе…·еӨҮжӣҙејәзҡ„зҹҘиҜҶе®№зәідёҺеӨҚжқӮе…ізі»е»әжЁЎиғҪеҠӣпјҢиҖҢжңӘиЎЁзҺ°еҮәжҳҺжҳҫзҡ„иҝҮжӢҹеҗҲиҝ№иұЎпјҢеӣ жӯӨе…¶е®№йҮҸдёҺжң¬д»»еҠЎзҡ„еӨҚжқӮжҖ§жӣҙдёәеҢ№й…ҚпҪЎ
иЎЁ 3 жЁЎеһӢеҸӮ数规模еҫ®и°ғиҜ„еҲҶжұҮжҖ»

第 2 з»„иҜ•йӘҢй’ҲеҜ№е…ій”®и®ӯз»ғи¶…еҸӮж•°иҝӣиЎҢдјҳеҢ–пҪЎжү№йҮҸеӨ§е°Ҹ (Batch Size) зӣҙжҺҘеҪұе“ҚжўҜеәҰдј°и®Ўзҡ„зЁіе®ҡжҖ§дёҺи®ӯз»ғж•ҲзҺҮпҪЎиҜ•йӘҢеҜ№жҜ”дәҶ Batch Size дёә 8 е’Ң 16 зҡ„и®ҫзҪ®пҪЎиЎЁ 4 з»“жһңжҳҫзӨәпјҢ ж—¶жЁЎеһӢеҸ–еҫ—дәҶжңҖдҪізҡ„з»јеҗҲиҜ„еҲҶ (жҖ»еҲҶ 7.5)пҪЎиҫғеӨ§зҡ„ Batch Size еҸҜиғҪеңЁжң¬иҜ•йӘҢжқЎд»¶дёӢжҸҗдҫӣдәҶжӣҙзЁіе®ҡпҪӨеҷӘеЈ°жӣҙдҪҺзҡ„жўҜеәҰж–№еҗ‘пјҢд»ҺиҖҢдҪҝжЁЎеһӢеңЁжңүйҷҗзҡ„ж•°жҚ®дёҠеӯҰд№ еҲ°жӣҙжіӣеҢ–зҡ„йўҶеҹҹиЎЁеҫҒпјҢиҖҢйқһи®°еҝҶи®ӯз»ғж ·жң¬зҡ„з»ҶиҠӮпҪЎеҹәдәҺд»ҘдёҠдёӨз»„иҜ•йӘҢпјҢжң¬з ”究жңҖз»ҲйҖүе®ҡ DeepSeek-R1-Distill-Qwen-7B дҪңдёәеҹәеә§жЁЎеһӢпјҢ并йҮҮз”Ё Batch зӯүеҸӮж•°иҝӣиЎҢеҗҺз»ӯеҫ®и°ғпҪЎи®ӯз»ғиҝҮзЁӢе…ұ 20 иҪ®пјҢ并е®ҡжңҹдҝқеӯҳжЈҖжҹҘзӮ№д»ҘдҫӣеҲҶжһҗпҪЎ
иЎЁ 4 жЁЎеһӢеҫ®и°ғеҸӮж•°иҜ•йӘҢиҜ„еҲҶжұҮжҖ»

2.2 еҫ®и°ғиҝҮзЁӢеҲҶжһҗ
е°ҶеүҚжңҹжҸҗеҸ–并еӨ„зҗҶеҫ—еҲ°зҡ„ 35019 жқЎж•°жҚ®йӣҶжҢүз…§и®ӯз»ғйӣҶдёҺжөӢиҜ•йӣҶ 9:1 зҡ„жҜ”дҫӢйҡҸжңәеҲ’еҲҶпјҢдҪңдёәи®ӯз»ғж•°жҚ®ејҖе§ӢжЁЎеһӢзҡ„еҫ®и°ғе·ҘдҪңпҪЎжЁЎеһӢзҡ„и®ӯз»ғеҠЁжҖҒжҳҜиҜ„дј°е…¶еӯҰд№ зҠ¶жҖҒзҡ„йҮҚиҰҒдҫқжҚ®пҪЎеӣҫ 4 жүҖзӨәдёә LoRA еҫ®и°ғиҝҮзЁӢдёӯзҡ„и®ӯз»ғжҚҹеӨұдёҺиҜ„дј°жҚҹеӨұжӣІзәҝпҪЎеҸҜд»Ҙи§ӮеҜҹеҲ°пјҢи®ӯз»ғжҚҹеӨұжҢҒз»ӯе№ізЁідёӢйҷҚпјҢиЎЁжҳҺжЁЎеһӢеңЁжңүж•Ҳең°еӯҰд№ д»»еҠЎпҪЎз„¶иҖҢпјҢиҜ„дј°жҚҹеӨұеңЁзәҰ 200 жӯҘеҗҺејҖе§Ӣе‘ҲзҺ°дёҠеҚҮи¶ӢеҠҝпҪЎиҝҷжҳҜдёҖдёӘз»Ҹе…ёзҡ„иҝҮжӢҹеҗҲдҝЎеҸ·пјҢж„Ҹе‘ізқҖжЁЎеһӢејҖе§ӢиҝҮеәҰйҖӮеә”и®ӯз»ғйӣҶзҡ„зү№жңүеҷӘеЈ°жҲ–зү№е®ҡжЁЎејҸпјҢд»ҺиҖҢеҜјиҮҙе…¶еңЁжңӘи§ҒиҝҮж•°жҚ®дёҠзҡ„жіӣеҢ–иғҪеҠӣдёӢйҷҚпҪЎдёәж·ұе…ҘжҺўз©¶жӯӨзҺ°иұЎе№¶зЎ®е®ҡжңҖдјҳжЁЎеһӢеҝ«з…§пјҢжң¬з ”究йҖүеҸ–дәҶ 3 дёӘе…ёеһӢйҳ¶ж®өзҡ„жЈҖжҹҘзӮ№иҝӣиЎҢеҲҶжһҗпјҡи®ӯз»ғеҲқжңҹ (step=100пјҢ, жҚҹеӨұдёӢйҷҚжңҹ)пҪӨиҜ„дј°жҚҹеӨұжңҖдҪҺзӮ№пјҲstep=360пјүд»ҘеҸҠи®ӯз»ғжң«жңҹ (step=700, жҚҹеӨұдёҠеҚҮжңҹ)пҪЎдёәдәҶиҠӮзңҒз®—еҠӣиө„жәҗпјҢеңЁзӣ‘жөӢеҲ° eval_loss жңүдёҠеҚҮи¶ӢеҠҝд№ӢеҗҺеҸҜд»ҘиҝӣиЎҢж—©еҒңеӨ„зҗҶпјҢиҠӮзәҰз®—еҠӣзҡ„еҗҢж—¶иҝҳиғҪиҠӮзәҰдёҖе®ҡзҡ„ж—¶й—ҙжҲҗжң¬пҪЎ
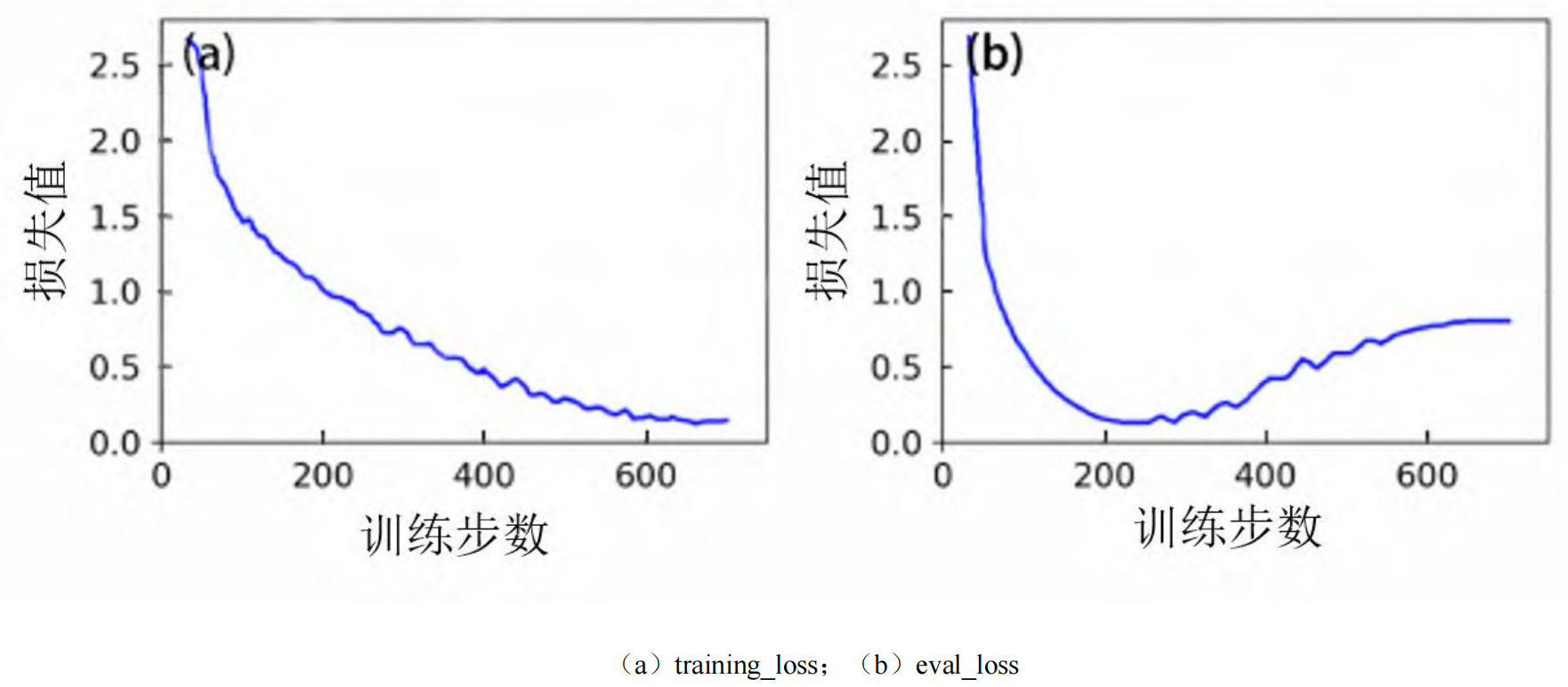
еӣҫ 4 LoRA еҫ®и°ғжҚҹеӨұжӣІзәҝ
2.3 жөӢиҜ„з»“жһңеҲҶжһҗ
йҰ–е…ҲдҪҝз”Ёеҹәеә§жЁЎеһӢеҚіжңӘз»ҸиҝҮеҫ®и°ғи®ӯз»ғзҡ„йў„и®ӯз»ғжЁЎеһӢдёҺз»ҸиҝҮеҫ®и°ғзҡ„жЁЎеһӢиҝӣиЎҢжҺЁзҗҶж•Ҳжһңзҡ„еҜ№жҜ”пјҢз»“жһңи§ҒиЎЁ 5пҪЎйҖүеҸ–дёӨиҖ…дёӯжҹҗзӣёеҗҢиҫ“е…ҘжҹҘзңӢиҫ“еҮәз»“жһңеҸҜд»ҘеҸ‘зҺ°пјҢйў„и®ӯз»ғжЁЎеһӢзҡ„иҫ“еҮәд»…жҳҜеңЁй—®йўҳеҗҺдҫқж—§иҝӣиЎҢж–Үеӯ—жҺҘйҫҷзҡ„еҶ…е®№пјҢиҫ“еҮәй•ҝеәҰз”ҡиҮіиғҪиҫҫеҲ°йҷҗеҲ¶зҡ„жңҖеӨ§ token еҖјпјҢе…¶дёӯиҷҪ然иғҪзңӢеҲ°дёҖе®ҡзҡ„иҜӯиЁҖйҖ»иҫ‘жҖ§пјҢдҪҶжҳҜеҜ№дәҺиҜҘй—®йўҳжҠ‘жҲ–жҳҜзғ§з»“йўҶеҹҹжқҘиҜҙеқҮж— жӯЈзЎ®жҖ§еҸҜиЁҖпҪЎз»ҸиҝҮеҫ®и°ғеҗҺзҡ„йў„и®ӯз»ғжЁЎеһӢеҲҷжҳҜй’ҲеҜ№й—®йўҳеҒҡеҮәдәҶжҺЁзҗҶд»ҘеҸҠеӣһзӯ”пјҢдёҚд»…еӯҰд№ еҲ°дәҶиҜӯиЁҖзҡ„йҖ»иҫ‘жҖ§пјҢиҝҳж №жҚ®жҸҗдҫӣзҡ„зғ§з»“и®ӯз»ғж•°жҚ®еҸҚйҰҲдәҶиҫ“е…Ҙй—®йўҳзӣёе…ізҡ„еҶ…е®№пјҢжӯЈзЎ®жҖ§д№ҹжңүжҳҫи‘—зҡ„жҸҗеҚҮпјҢиҝҷејәжңүеҠӣең°иҜҒжҳҺдәҶй’ҲеҜ№еһӮзӣҙйўҶеҹҹиҝӣиЎҢеҸӮж•°й«ҳж•ҲйҖӮй…ҚжҳҜжҝҖжҙ»еӨ§иҜӯиЁҖжЁЎеһӢдё“дёҡзҹҘиҜҶзҡ„еҝ…иҰҒйҖ”еҫ„пҪЎ
иЎЁ 5 жЁЎеһӢжҳҜеҗҰеҫ®и°ғиҜ„еҲҶжұҮжҖ»

еңЁи®ӯз»ғжЈҖжҹҘзӮ№дёҺжіӣеҢ–иғҪеҠӣзҡ„е…ізі»ж–№йқўпјҢеҜ№ 3 дёӘжЈҖжҹҘзӮ№зҡ„жөӢиҜ„з»“жһң (иЎЁ 6) дёҺжҚҹеӨұжӣІзәҝжҸӯзӨәзҡ„и¶ӢеҠҝе®Ңе…Ёеҗ»еҗҲпјҡиҜ„дј°жҚҹеӨұжңҖдҪҺзӮ№ (step=360) зҡ„жЁЎеһӢеҸ–еҫ—дәҶжңҖдҪіжҖ§иғҪ (жҖ»еҲҶ 7.5)пҪЎи®ӯз»ғеҲқжңҹжЁЎеһӢ (step=100) е°ҡжңӘе……еҲҶеӯҰд№ пјҢиҖҢи®ӯз»ғжң«жңҹзҡ„жЁЎеһӢ (step=700) иҷҪи®ӯз»ғжҚҹеӨұжӣҙдҪҺпјҢдҪҶеӣ иҝҮжӢҹеҗҲеҜјиҮҙе…¶жӯЈзЎ®жҖ§жҳҫи‘—дёӢйҷҚ (3.9 vs. 4.9 жӯӨз»“жһңиҜҒе®һдәҶйҮҮз”Ё вҖңж—©еҒңвҖқ зӯ–з•ҘпҪӨйҖүжӢ©иҜ„дј°жҚҹеӨұжңҖдҪҺзӮ№жЁЎеһӢзҡ„жңүж•ҲжҖ§пјҢе®ғжҳҜе№іиЎЎжЁЎеһӢеӯҰд№ е……еҲҶжҖ§дёҺжіӣеҢ–иғҪеҠӣзҡ„е…ій”®пҪЎ
иЎЁ 6 жЁЎеһӢжЈҖжҹҘзӮ№иҜ„еҲҶжұҮжҖ»
еңЁжЈҖзҙўеўһејәз”ҹжҲҗ (RAG) зҡ„еўһзӣҠж•Ҳжһңж–№йқўпјҢе°Ҷзғ§з»“йўҶеҹҹзӣёе…ізҡ„д№ҰзұҚпҪӨеӯҰжңҜж–ҮзҢ®зӯүз»ҸиҝҮеөҢе…ҘпҪӨеҲҮзүҮеҗҺдҪңдёәеҸҜдҫӣжЁЎеһӢеҸӮиҖғзҡ„зҹҘиҜҶеә“пҪЎжңҖдјҳеҫ®и°ғжЁЎеһӢеҹәзЎҖдёҠеј•е…Ҙ RAG жңәеҲ¶еҗҺпјҢжЁЎеһӢжҖ§иғҪеҫ—еҲ°иҝӣдёҖжӯҘжҸҗеҚҮ (иЎЁ 7)пҪЎйҖ»иҫ‘жҖ§иҜ„еҲҶд»Һ 2.6 е°Ҹе№…жҸҗй«ҳиҮі 2.8, иҖҢжӯЈзЎ®жҖ§иҜ„еҲҶе®һзҺ°дәҶд»Һ 4.9 еҲ° 6.5 зҡ„жҳҫи‘—и·ғеҚҮпјҢжҖ»еҲҶиҫҫеҲ° 9.2пҪЎ иҝҷдёҖзҺ°иұЎе…·жңүж·ұеҲ»еҗ«д№үпјҡLoRA еҫ®и°ғдҪҝжЁЎеһӢжҺҢжҸЎдәҶзғ§з»“йўҶеҹҹзҡ„ вҖңиҜӯиЁҖвҖқ е’ҢеҹәзЎҖ вҖңзҹҘиҜҶжЎҶжһ¶вҖқ, иҖҢ RAG жңәеҲ¶еҲҷдёәжЁЎеһӢеңЁеӣһзӯ”е…·дҪ“й—®йўҳж—¶еҠЁжҖҒжҸҗдҫӣдәҶзІҫеҮҶзҡ„ вҖңдәӢе®һдҫқжҚ®вҖқ е’Ң вҖңе·ҘиүәзәҰжқҹвҖқпҪЎдёӨиҖ…зҡ„з»“еҗҲпјҢжң¬иҙЁдёҠжҳҜе°ҶеӨ§жЁЎеһӢзҡ„ејәеӨ§з”ҹжҲҗжҺЁзҗҶиғҪеҠӣпјҢдёҺеӨ–йғЁзҹҘиҜҶеә“зҡ„зІҫзЎ®жҖ§пҪӨжқғеЁҒжҖ§иҝӣиЎҢдәҶж·ұеәҰиһҚеҗҲпјҢд»ҺиҖҢеңЁж №жң¬дёҠзј“и§ЈдәҶжЁЎеһӢзҡ„ вҖңе№»и§үвҖқ й—®йўҳпјҢдҪҝзі»з»ҹиҫ“еҮәдёҚд»…жөҒз•…еҗҲзҗҶпјҢиҖҢдё”й«ҳеәҰеҸҜйқ пҪӨз¬ҰеҗҲйўҶеҹҹ规иҢғпҪЎдёҺзҺ°йҳ¶ж®өзҡ„йҖҡз”ЁеӨ§жЁЎеһӢ (Chat GPT) зӣёжҜ”пјҢжң¬з ”究зјәе°‘дәҶжЁЎеһӢзҡ„ж·ұеәҰжҖқиҖғдёҺиҒ”зҪ‘жҖқиҖғиғҪеҠӣпјҢдҪҶжҳҜе®Ңе…ЁеңЁеһӮзӣҙйўҶеҹҹиҝӣиЎҢи®ӯз»ғдёҺзҹҘиҜҶеә“жҗӯе»әдҪҝеҫ—жң¬жЁЎеһӢеңЁдәӢе®һеҮҶзЎ®жҖ§е’ҢйўҶеҹҹеҗҲ规жҖ§дёҠйғҪдјҳдәҺ Chat GPTпҪЎиҝҷдёәжһ„е»әеҸҜз”ЁдәҺдёҘиӮғе·Ҙдёҡиҫ…еҠ©еҶізӯ–зҡ„ AI зі»з»ҹжҸҗдҫӣдәҶеҸҜйқ зҡ„жҠҖжңҜи·Ҝеҫ„пҪЎ
иЎЁ 7 жЁЎеһӢ RAG иҜ„еҲҶжұҮжҖ»

3 жҷәиғҪй—®зӯ”зі»з»ҹ
3.1 зі»з»ҹи®ҫи®Ў
дёәе®һзҺ°зғ§з»“е·ҘиүәжҷәиғҪй—®зӯ”дёҺиҜҠж–ӯжЁЎеһӢзҡ„иҗҪең°еә”з”ЁпјҢжң¬з ”究и®ҫ计并ејҖеҸ‘дәҶдёҖеҘ—е®Ңж•ҙзҡ„дәӨдә’ејҸзі»з»ҹпҪЎиҜҘзі»з»ҹйҮҮз”ЁеүҚеҗҺз«ҜеҲҶзҰ»жһ¶жһ„пјҢж—ЁеңЁдёәз”ЁжҲ·жҸҗдҫӣзӣҙи§ӮпҪӨзЁіе®ҡдё”дё“дёҡзҡ„йўҶеҹҹжҷәиғҪй—®зӯ”жңҚеҠЎпҪЎзі»з»ҹж•ҙдҪ“жһ¶жһ„з”ұ 3 дёӘж ёеҝғжЁЎеқ—жһ„жҲҗпјҢеүҚз«ҜдәӨдә’з•ҢйқўеҹәдәҺ Vue.js жЎҶжһ¶ејҖеҸ‘пјҢеҲ©з”Ё HTMLпҪӨCSS дёҺ JavaScript жһ„е»әдәҶз®ҖжҙҒжҳҺдәҶзҡ„ Web з•ҢйқўпҪЎиҜҘз•ҢйқўжҸҗдҫӣжЁЎеһӢеҜ№иҜқпҪӨеӨҡиҪ®дјҡиҜқеҺҶеҸІз®ЎзҗҶпҪӨзӯ”жЎҲж јејҸеҢ–жёІжҹ“ (ж”ҜжҢҒе…ій”®иҜҚеҠ зІ—пҪӨеҢ–еӯҰејҸдёҺе…¬ејҸ规иҢғжҳҫзӨә) еҸҠдјҡиҜқи®°еҪ•еҜјеҮәзӯүеҠҹиғҪпјҢиҮҙеҠӣдәҺжҸҗеҚҮз”ЁжҲ·дҪ“йӘҢпҪЎеҗҺз«Ҝ API жңҚеҠЎйҮҮз”ЁиҪ»йҮҸзә§ Flask жЎҶжһ¶жһ„е»ә RESTful API, дҪңдёәиҝһжҺҘеүҚз«ҜдёҺж ёеҝғжЁЎеһӢеј•ж“Һзҡ„жЎҘжўҒпҪЎеҗҺз«ҜиҙҹиҙЈжҺҘ收用жҲ·жҹҘиҜўпјҢеҚҸи°ғи°ғеәҰеӨ§иҜӯиЁҖжЁЎеһӢжҺЁзҗҶдёҺ RAG жЈҖзҙўжөҒзЁӢпјҢ并е°Ҷз»“жһ„еҢ–з»“жһңиҝ”еӣһеүҚз«ҜпҪЎж ёеҝғжЁЎеһӢеј•ж“ҺдҪңдёәзі»з»ҹзҡ„ вҖңжҷәиғҪдёӯжһўвҖқ, йӣҶжҲҗдәҶз»ҸиҝҮ LoRA еҫ®и°ғзҡ„зғ§з»“йўҶеҹҹеӨ§иҜӯиЁҖжЁЎеһӢдёҺ RAG жЈҖзҙўжЁЎеқ—пҪЎиҜҘеј•ж“ҺжҺҘ收еҗҺз«Ҝи°ғеәҰпјҢе®ҢжҲҗеҜ№з”ЁжҲ·й—®йўҳзҡ„ж·ұеәҰиҜӯд№үзҗҶи§ЈпҪӨзҹҘиҜҶжЈҖзҙўдёҺзӯ”жЎҲз”ҹжҲҗпҪЎиҜҘи®ҫи®ЎзЎ®дҝқдәҶзі»з»ҹзҡ„жЁЎеқ—еҢ–пҪӨеҸҜз»ҙжҠӨжҖ§дёҺеҸҜжү©еұ•жҖ§пјҢдҫҝдәҺжңӘжқҘеҠҹиғҪзҡ„иҝӯд»ЈдёҺжЁЎеһӢеҚҮзә§пҪЎ
3.2 зі»з»ҹиҝҗиЎҢ
зі»з»ҹиҝҗиЎҢеүҚпјҢйңҖдҫқж¬ЎеҗҜеҠЁж ёеҝғжЁЎеһӢжңҚеҠЎпҪӨеҠ иҪҪ RAG еҗ‘йҮҸзҹҘиҜҶеә“并йғЁзҪІеүҚеҗҺз«Ҝеә”з”ЁпҪЎз”ЁжҲ·йҖҡиҝҮжөҸи§ҲеҷЁи®ҝй—®з»ҹдёҖе…ҘеҸЈеҚіеҸҜдҪҝз”ЁпҪЎзі»з»ҹиҝҗиЎҢжөҒзЁӢеҢ…жӢ¬еҗҜеҠЁеӨ§иҜӯиЁҖжЁЎеһӢжңҚеҠЎпҪӨжҺҘе…Ҙ RAG жЈҖзҙўжЁЎеқ—дёҺйғЁзҪІеүҚз«Ҝеә”з”ЁпҪЎ з”ЁжҲ·йҖҡиҝҮ Web жөҸи§ҲеҷЁи®ҝй—®зі»з»ҹеҗҺпјҢеҸҜдёҺжЁЎеһӢиҝӣиЎҢеӨҡиҪ®еҜ№иҜқпҪЎзі»з»ҹиғҪеӨҹжңүж•ҲеӨ„зҗҶеҗ„зұ»зғ§з»“е·Ҙиүәй—®йўҳпҪЎеҰӮеӣҫ5зӨәдҫӢжүҖзӨәпјҢй’ҲеҜ№ вҖңзғ§з»“иҝҮзЁӢдёӯзҮғж–ҷзҡ„зҮғзғ§еҜ№зғ§з»“зҹҝиҙЁйҮҸжңүе“ӘдәӣеҪұе“ҚпјҹвҖқ иҝҷдёҖдё“дёҡй—®йўҳпјҢзі»з»ҹз”ҹжҲҗзҡ„зӯ”жЎҲжқЎзҗҶжё…жҷ°пҪЎиҝҷйӘҢиҜҒдәҶзі»з»ҹеңЁдё“дёҡзҹҘиҜҶе‘ҲзҺ°дёҠзҡ„еҸҜйқ жҖ§дёҺе®һз”ЁжҖ§пјҢдҪҝе…¶иғҪеӨҹзңҹжӯЈжңҚеҠЎдәҺзғ§з»“е·Ҙиүәзҡ„иҫ…еҠ©еҲҶжһҗпҪӨе‘ҳе·Ҙеҹ№и®ӯдёҺеҶізӯ–ж”ҜжҢҒпҪЎ

еӣҫ 5 зғ§з»“е·Ҙиүәжҷәж…§й—®зӯ”зӨәдҫӢ
4 жҖ»з»“дёҺеұ•жңӣ
4.1 жҖ»з»“
жң¬ж–Үйқўеҗ‘зғ§з»“е·ҘиүәжҷәиғҪеҢ–иҪ¬еһӢдёӯзҹҘиҜҶеҲ©з”ЁдёҚи¶ідёҺеҶізӯ–дҫқиө–з»ҸйӘҢзҡ„жҢ‘жҲҳпјҢжһ„е»әдәҶдёҖеҘ—еҹәдәҺеӨ§иҜӯиЁҖжЁЎеһӢ (LLM) зҡ„зғ§з»“е·ҘиүәжҷәиғҪй—®зӯ”дёҺиҜҠж–ӯзі»з»ҹпҪЎж ёеҝғе·ҘдҪңдёҺз»“и®әеҰӮдёӢ:
1) жһ„е»әдәҶй«ҳиҙЁйҮҸзҡ„зғ§з»“е·ҘиүәеһӮзӣҙйўҶеҹҹж•°жҚ®йӣҶпҪЎи®ҫи®ЎдәҶдёҖеҘ—д»ҺеӨҡжәҗйқһз»“жһ„еҢ–ж–Үжң¬еҲ°й—®зӯ”еҜ№зҡ„иҮӘеҠЁеҢ–жһ„е»әжөҒзЁӢпјҢз»Ҹдәәе·Ҙе®Ўж ёеҪўжҲҗеҢ…еҗ« 35 019 жқЎзҡ„й«ҳиҙЁйҮҸж•°жҚ®пјҢдёәжЁЎеһӢеҫ®и°ғдёҺжЈҖзҙўеўһејәз”ҹжҲҗ (RAG) еҘ е®ҡдәҶзҹҘиҜҶеҹәзЎҖпҪЎ
2) жҺўзҙўе№¶йӘҢиҜҒдәҶйҖӮз”ЁдәҺзғ§з»“йўҶеҹҹзҡ„ LLM й«ҳж•ҲйҖӮй…ҚдёҺеўһејәж–№жі•пҪЎйҖҡиҝҮзі»з»ҹжҖ§зҡ„еҸӮж•°иҜ•йӘҢпјҢзЎ®е®ҡдәҶеңЁзҺ°жңүж•°жҚ®дёҺз®—еҠӣжқЎд»¶дёӢпјҢйҮҮз”Ё 7B еҸӮж•°жЁЎеһӢ并结еҗҲ LoRA еҫ®и°ғеҸҜиҺ·еҫ—жңҖдҪіжҖ§иғҪпҪЎиҜ•йӘҢиҝӣдёҖжӯҘиЎЁжҳҺпјҢеј•е…Ҙ RAG жңәеҲ¶иғҪжңүж•ҲеҲ©з”ЁеӨ–йғЁзҹҘиҜҶеә“пјҢжҳҫи‘—жҸҗеҚҮжЁЎеһӢз”ҹжҲҗзӯ”жЎҲзҡ„дәӢе®һеҮҶзЎ®жҖ§дёҺйўҶеҹҹеҗҲ规жҖ§пјҢж•ҙдҪ“жЁЎеһӢиҜ„еҲҶд»Һеҹәеә§жЁЎеһӢзҡ„ 1.9 жҸҗеҚҮиҮі 9.2 (ж»ЎеҲҶ 10.0), дёәи§ЈеҶіеӨҚжқӮе·Ҙиүәй—®йўҳжҸҗдҫӣдәҶ вҖңзҹҘиҜҶеўһејәвҖқ зҡ„еҸҜйқ и·Ҝеҫ„пҪЎ
3) ејҖеҸ‘дәҶеҸҜдәӨдә’зҡ„зі»з»ҹеҺҹеһӢпҪЎйӣҶжҲҗеҫ®и°ғжЁЎеһӢпҪӨRAG жЁЎеқ—дёҺеүҚеҗҺз«Ҝз•ҢйқўпјҢе®һзҺ°дәҶзҒөжҙ»и°ғз”ЁдёҺеӨҡиҪ®еҜ№иҜқпјҢйӘҢиҜҒдәҶжҠҖжңҜи·Ҝзәҝзҡ„еҸҜиЎҢжҖ§пҪЎ
з»јдёҠжүҖиҝ°пјҢжң¬з ”究йҖҡиҝҮ вҖңйўҶеҹҹж•°жҚ®жһ„е»ә - жЁЎеһӢй«ҳж•Ҳеҫ®и°ғ - зҹҘиҜҶеҠЁжҖҒеўһејәвҖқ зҡ„жҠҖжңҜи·Ҝеҫ„пјҢе°ҶйҖҡз”ЁеӨ§жЁЎеһӢиҪ¬еҢ–дёәе…·еӨҮзғ§з»“дё“дёҡзҹҘиҜҶзҡ„жҷәиғҪдҪ“пјҢдёәжөҒзЁӢе·Ҙдёҡзҡ„йҡҗжҖ§зҹҘиҜҶж•°еӯ—еҢ–дёҺжҷәиғҪеҢ–еә”з”ЁжҸҗдҫӣдәҶе®һи·өиҢғдҫӢгҖӮ
4.2 еұҖйҷҗжҖ§
жң¬з ”究д»ҚеӯҳеңЁдёҖе®ҡзҡ„еұҖйҷҗжҖ§пҪЎйҰ–е…ҲпјҢжүҖжһ„е»әж•°жҚ®йӣҶзҡ„规模дёҺзҹҘиҜҶиҰҶзӣ–иҢғеӣҙд»ҚжңүжҸҗеҚҮз©әй—ҙпјҢиҝҷеңЁдёҖе®ҡзЁӢеәҰдёҠйҷҗеҲ¶дәҶжЁЎеһӢеҜ№жӣҙеӨҚжқӮпҪӨзҪ•и§Ғе·ҘеҶөзҡ„жіӣеҢ–дёҺжҺЁзҗҶиғҪеҠӣпҪЎе…¶ж¬ЎпјҢеҸ—йҷҗдәҺз®—еҠӣиө„жәҗпјҢжң¬з ”究жңӘиғҪжҺўзҙўеҸӮж•°йҮҸжӣҙеӨ§зҡ„еҹәеә§жЁЎеһӢпјҢе…¶жҪңеңЁзҡ„жӣҙејәжҺЁзҗҶиғҪеҠӣжңүеҫ…еңЁжңӘжқҘе·ҘдҪңдёӯйӘҢиҜҒпҪЎжӯӨеӨ–пјҢеҪ“еүҚзі»з»ҹдё»иҰҒеӨ„зҗҶж–Үжң¬дҝЎжҒҜпјҢе°ҡжңӘйӣҶжҲҗз”ҹдә§зҺ°еңәзҡ„е®һж—¶дј ж„ҹеҷЁж•°жҚ®дёҺеӣҫеғҸдҝЎжҒҜпјҢеңЁе®һзҺ°дёҺзү©зҗҶиҝҮзЁӢзҡ„ж·ұеәҰй—ӯзҺҜдәӨдә’ж–№йқўеӯҳеңЁдёҚи¶іпҪЎ
4.3 жңӘжқҘеұ•жңӣ
жңӘжқҘе·ҘдҪңеҸҜд»Ҙд»Һд»ҘдёӢ 3 дёӘж–№йқўж·ұе…ҘејҖеұ•пјҡ第дёҖпјҢжҢҒз»ӯжү©е……дёҺдјҳеҢ–йўҶеҹҹж•°жҚ®йӣҶпјҢзәіе…ҘжӣҙеӨҡе…ғзҡ„жЎҲдҫӢпҪӨжӣҙзҝ”е®һзҡ„е·ҘиүәжүӢеҶҢеҸҠй«ҳиҙЁйҮҸзҡ„专家з»ҸйӘҢи®°еҪ•пјҢеӨҜе®һжЁЎеһӢзҡ„зҹҘиҜҶеҹәзЎҖпҪЎз¬¬дәҢпјҢжҺўзҙўжӣҙе…Ҳиҝӣзҡ„жЁЎеһӢдјҳеҢ–жҠҖжңҜпјҢдҫӢеҰӮеј•е…ҘеҹәдәҺдәәзұ»еҸҚйҰҲзҡ„ејәеҢ–еӯҰд№ (RLHF) жқҘеҫ®и°ғжЁЎеһӢиҫ“еҮәпјҢдҪҝе…¶жӣҙз¬ҰеҗҲе·ҘзЁӢеёҲзҡ„еҶізӯ–еҒҸеҘҪдёҺе®ү全规иҢғпҪЎз¬¬дёүпјҢжҺЁеҠЁзі»з»ҹеҗ‘еӨҡжЁЎжҖҒжҷәиғҪж–№еҗ‘еҸ‘еұ•пјҢиһҚеҗҲе®һж—¶дј ж„ҹеҷЁж•°жҚ®жөҒпҪӨи®ҫеӨҮиҝҗиЎҢеӣҫеғҸдёҺи§Ҷйў‘дҝЎжҒҜпјҢжһ„е»әиғҪеӨҹ вҖңж„ҹзҹҘ - зҗҶи§Ј - еҶізӯ–вҖқ зҡ„дёӢдёҖд»Јзғ§з»“е·ҘиүәжҷәиғҪдҪ“пјҢжңҖз»Ҳе®һзҺ°д»Һиҫ…еҠ©й—®зӯ”еҲ°й—ӯзҺҜдјҳеҢ–жҺ§еҲ¶зҡ„и·Ёи¶ҠпјҢеҲҮе®һжҺЁеҠЁзғ§з»“е·Ҙиүәзҡ„жҷәиғҪеҢ–иҝӣзЁӢпҪЎ
дҪңиҖ…пјҡзҺӢиҖҖзҘ– еҲҳж ©з‘һ и‘ЈзЈҠ йғӯиҙӨ еј е»әиүҜ еҲҳеҫҒе»ә
жҡӮж— иҜ„и®ә,зӯүдҪ жҠўжІҷеҸ‘

еҜ№иҜқдҫҜеә·йҖүпјҡ д»ҺвҖңжҠўдҝ®вҖқеҲ°вҖңйў„йҳІвҖқпјҢжҷәиғҪITиҝҗз»ҙзҡ„жӯЈзЎ®жү“ејҖж–№ејҸ

дёӯе°ҸдјҒдёҡж•°еӯ—еҢ–иҪ¬еһӢжЎҶжһ¶дёҺжҖ»и·Ҝзәҝеӣҫ